片间互联¶
未考虑网卡(Network Interface Card)¶
南桥和北桥¶
主要年代:1995~2005
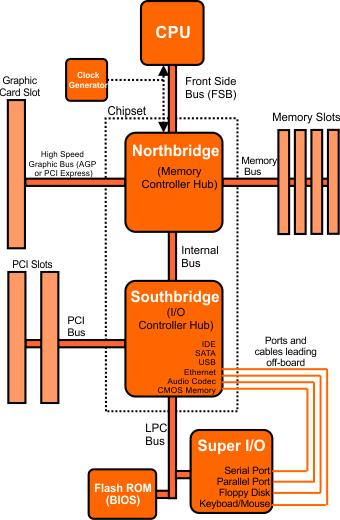
- 北桥负责连接:CPU、DDR、PCIE、南桥
- 南桥负责连接:PCI、USB、SATA、Ethernet、LPC、Super I/O
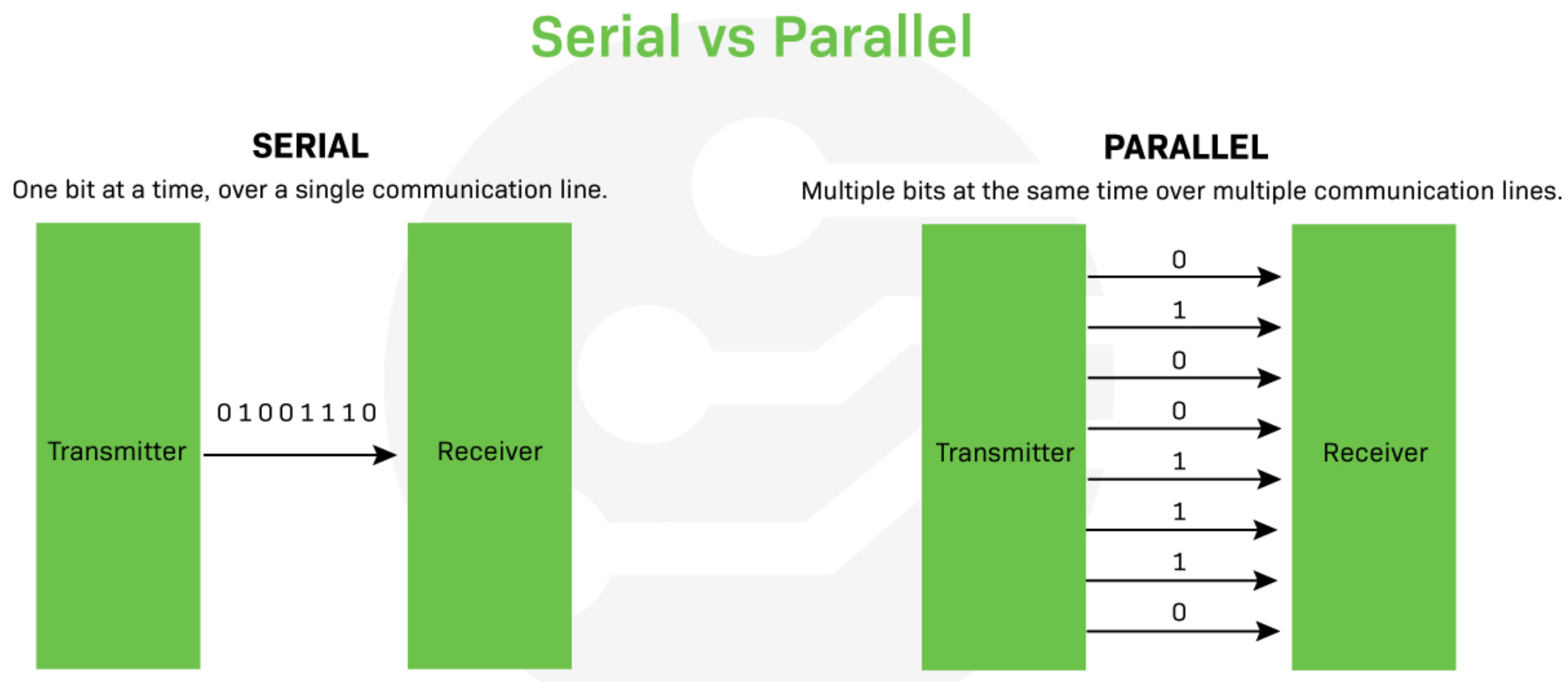
串行和并行总线:
仅北桥¶
主要年代:2010~至今
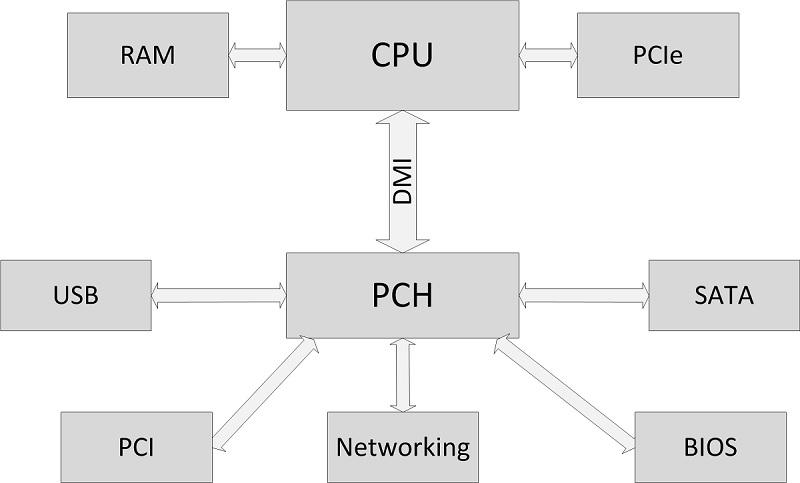
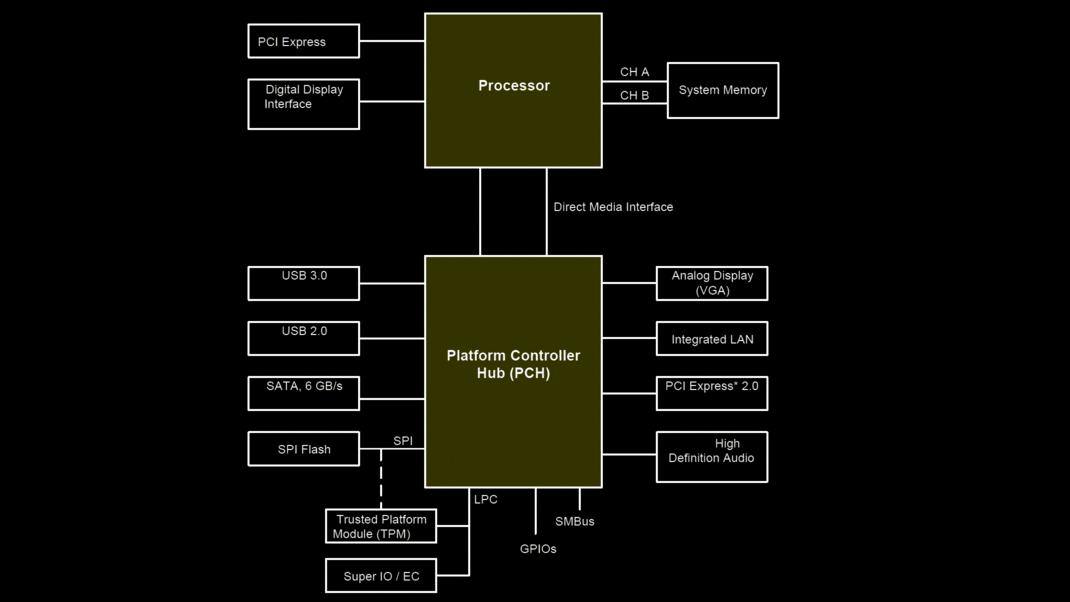
- DMI:Direct Media Interface
- PCH:Platform Controller Hub
CPU内置了原先的北桥功能(内存访问、PCIE RC),南桥演化为PCH。
PCIE¶
全称:Peripheral Component Interconnect Express。
总体抽象: - 系统层 -- PCIe分层交换互联结构 - 拓扑层 -- PCIe Tree(连接结构) - 协议层 -- TLP / DLLP / PHY
拓扑层¶
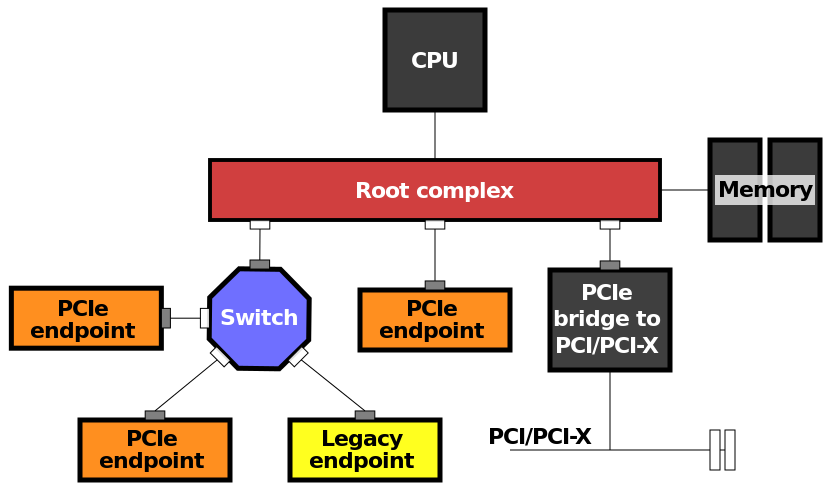
- Root Complex
- 整个PCIE拓扑的根节点。
- 负责连接CPU、内存和其他PCIE设备。
- 可以集成在CPU中,也可以单独使用一块芯片。
- 但是总体来说,PCIE还是需要一个主控的。
- Root Port:RC上的端口(主控侧端口)。可以有一个或者多个。
- Non-Root Port:非主控侧口。
- Endpoint:叶子节点上的设备。
- Switch:把一条上游PCIE路扩成多条下游PCIE路。
- upstream port:指向Root Complex。
- downstream port:背离Root Complex。
- switch的带宽要看upstream port带宽,所有downstream port汇聚带宽的上限是upstream port的带宽。

- Link:两个设备之间的一条连接。
- Lane是Link中的单条通道。
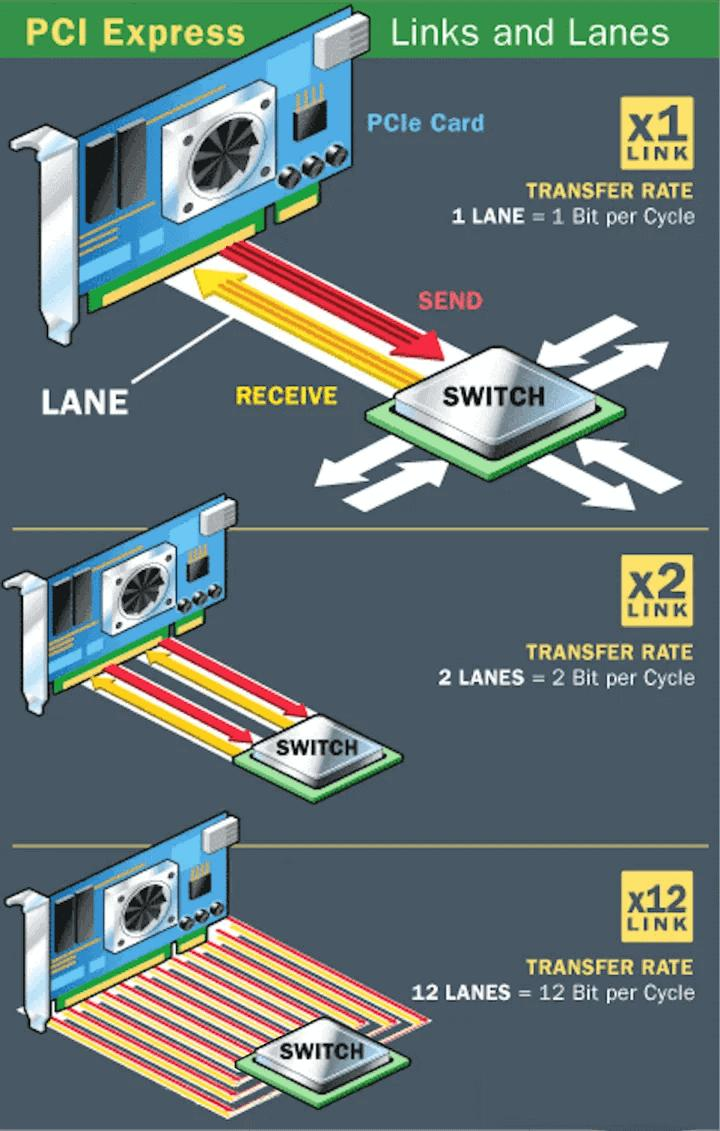

一条PCIE lane: - 一组独立的高速全双工串行通道。 - 由两对差分发送信号TX和差分接受信号RX组成。 - 差分信号指的是由两根线传输,信号 = (正线电压) - (负线电压)。 - 抗干扰、稳定。
常见lane数:x1 x2 x4 x8 x16

- PCI/PCI-X
- 共享并行总线
- 一条PCI总线上的设备会竞争带宽
系统层¶
拓扑层只说明如何连接。 系统层说明请求如何路由,互联网络运行机制。
-
PCIe系统的对象划分
- RC / Switch / Bridge
- 负责拓扑管理与事务转发。
- 维护层级、配置bus number和地址窗口、按规则路由TLP。
- Endpoint(GPU / NIC / NVMe等)
- 负责实现功能本体。
- 通过配置空间暴露BAR、能力结构、DMA能力等。
- BAR
- 设备配置空间中的寄存器。
- 描述设备需要的一段I/O或Memory窗口的大小、类型、属性。
- 系统枚举时给BAR分配地址。
- MMIO
- CPU侧对BAR资源的映射访问方式。
- CPU通过load/store访问设备寄存器,本质上会被RC转成PCIe Memory TLP。
- DMA
- 设备主动访问主机内存的机制。
- 大块数据搬运通常由DMA引擎完成,CPU只负责配置。
- IOMMU
- 负责把设备看到的DMA地址/IOVA翻译成CPU物理地址。
- ATS
- 设备侧缓存IOMMU翻译结果,降低地址翻译开销。
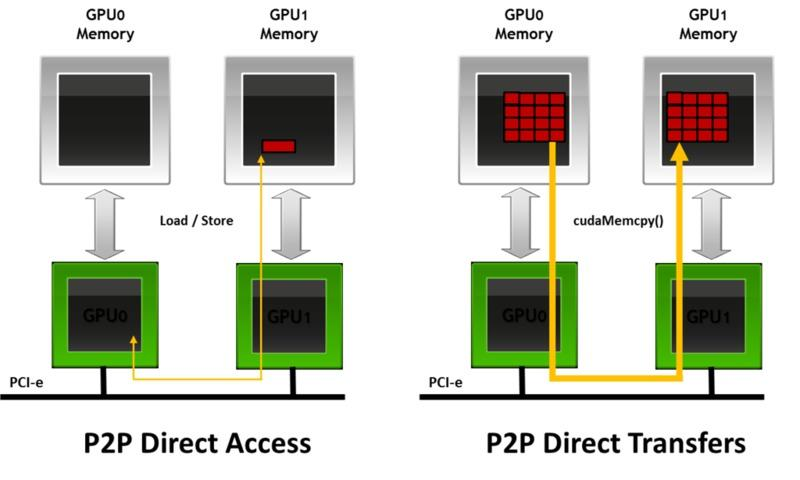
- P2P
- 设备直接访问另一设备暴露出来的BAR/peer aperture,不经过主机内存数据搬运。
- RC / Switch / Bridge
-
PCIe中的几类地址
- CPU虚拟地址
- CPU程序看到的地址,经CPU页表翻译后才变成CPU物理地址。
- CPU物理地址
- 主机DRAM和主机侧MMIO资源最终对应的物理地址。
- PCIe Memory Space / bus-visible address
- PCIe链路上传输、被Switch/Bridge用来路由的地址。
- DMA地址 / IOVA
- 设备访问主机内存时使用的device-visible地址。
- 不等于CPU虚拟地址,也不一定等于CPU物理地址。
- 本质上是PCIe Memory Space地址。
- peer BAR地址
- 设备访问另一个设备时使用的目标设备BAR/aperture地址。
- 本质上也是PCIe Memory Space地址,但目标是peer device,不是主机内存。
- CPU虚拟地址
-
过程思想:PCIe初始化与资源建立
-
RC从Root Port向下枚举整棵PCIe hierarchy。
-
遇到Bridge / Switch Port时,配置其下游bus number和地址窗口。
-
读取各设备配置空间,识别BAR、能力结构和功能类型。
-
为BAR分配I/O或Memory资源。
-
驱动将BAR资源映射成CPU可访问的MMIO区域。
-
若设备需要访问主机内存,则驱动进一步建立DMA映射,得到IOVA。
-
-
过程思想:三条核心访问路径
-
CPU -> Device
-
CPU通过MMIO访问设备BAR对应的寄存器或窗口。
-
MMIO对应的物理地址被RC转换成PCIe Memory地址。
-
路径:CPU -> RC -> Switch按地址窗口转发 -> Endpoint BAR decode。
-
-
Device -> Host Memory
-
驱动把DMA地址写入设备寄存器。
-
设备DMA引擎发起Memory Read/Write。
-
若地址不命中其他下游窗口,Switch就把事务送往upstream port,朝RC方向走。
-
IOMMU再把IOVA翻译成CPU物理地址,最终访问主存。
-
-
Device -> Device(P2P)
-
系统给目标设备暴露出的peer BAR/aperture分配PCIe地址。
-
发起设备对该地址发起Memory Read/Write。
-
Switch发现该地址命中目标设备所在downstream port的window,就直接转发给目标设备。
-
返回Completion时,再按Requester ID返回给发起者。
-
-
-
路由思想
-
配置访问:按bus number路由。
-
Memory / I/O访问:按地址窗口路由。
-
Completion返回:按Requester ID路由。
-
访问主机内存时,事务通常往上走;
-
访问peer device时,事务可能在Switch内部直接横向/向下转发。
-
-
总括
-
BAR/MMIO:CPU访问设备。
-
DMA/IOMMU/ATS:设备访问主机内存。
-
peer BAR/P2P:设备访问另一设备。
-
Switch/Bridge负责“路由”,Endpoint负责“地址认领与功能执行”。
-
PCIE 不同代际带宽¶
目前H200支持PCIE 5.0 x16。
PCIE 5.0 一条lane 的速率是 32GT/s (GigaTransfers per second)。
编码方式:128b/130b。(每完成130次传输,有128个有效bit)
由于是16lane,所以单向总带宽是 63GB/s。
CXL¶
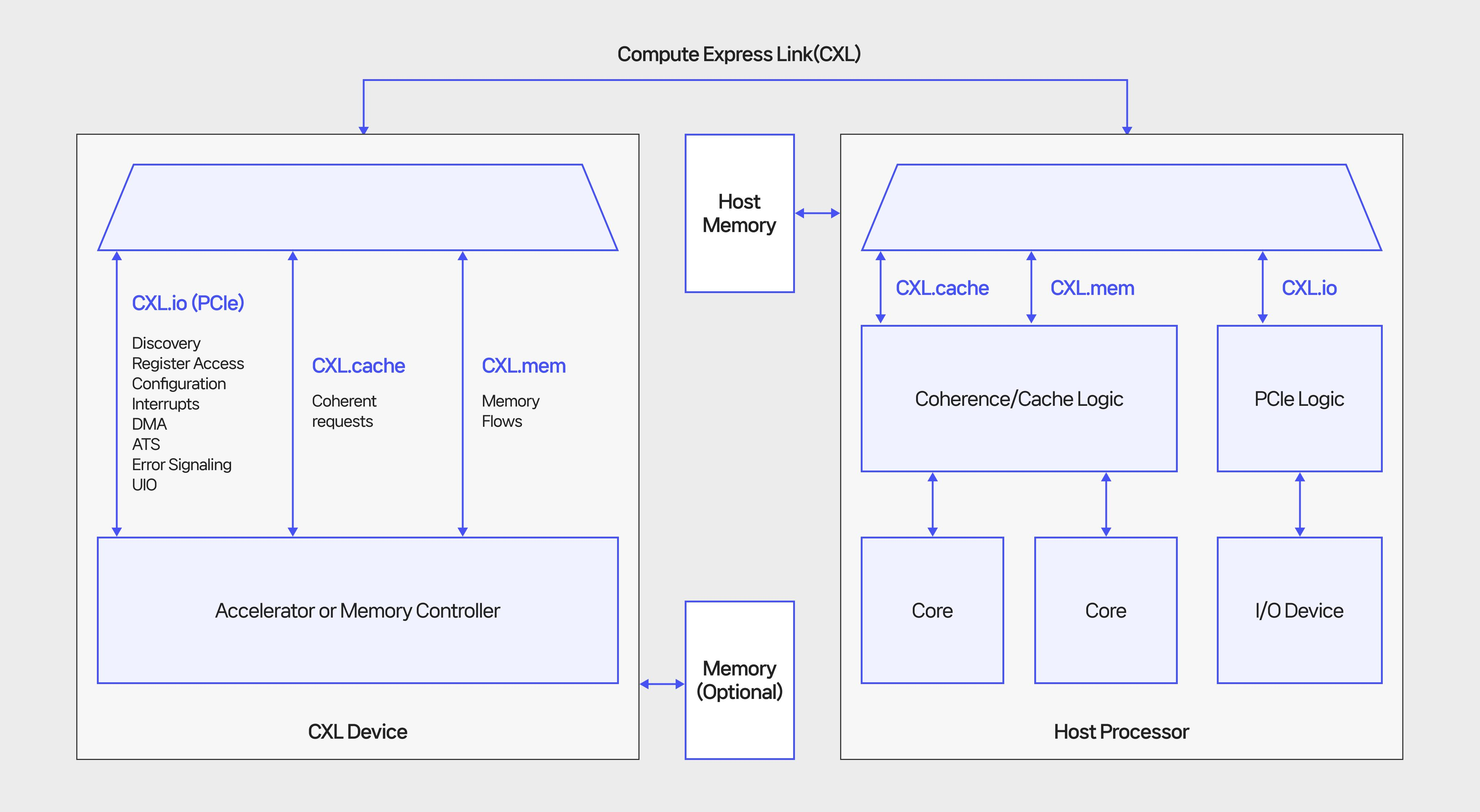
CXL:Compute Express Link。
CXL复用了PCIE的PHY层,并在其上运行CXL.io/CXL.cache/CXL.mem。 为CPU、加速器和内存设备提供缓存一致性与内存语义的高速互联Fabric。
PCIE: 1. CPU直连内存是“写回型、缓存一致”。 2. 设备通过DMA访问内存时,一般不考虑Cache Coherent。进而需要处理可能会引发的一系列问题。 3. CPU通过MMIO访问设备内存。
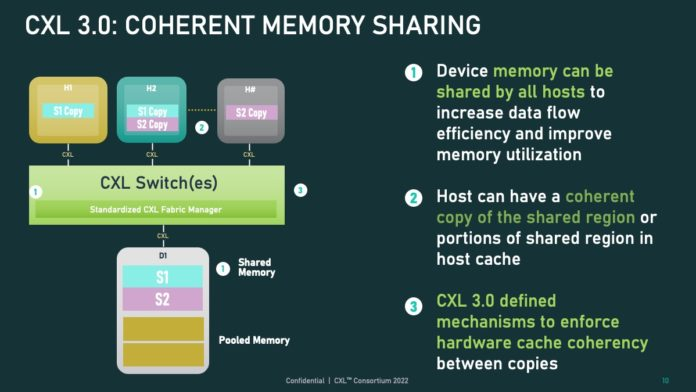
CXL: - 设备通过 Memory Load/Store 进行 Coherent 访问主机内存。 - 主机可以通过CXL将设备内存作为可寻址的内存资源,并且通过 Memory Load/Store 进行 Coherent 访问。
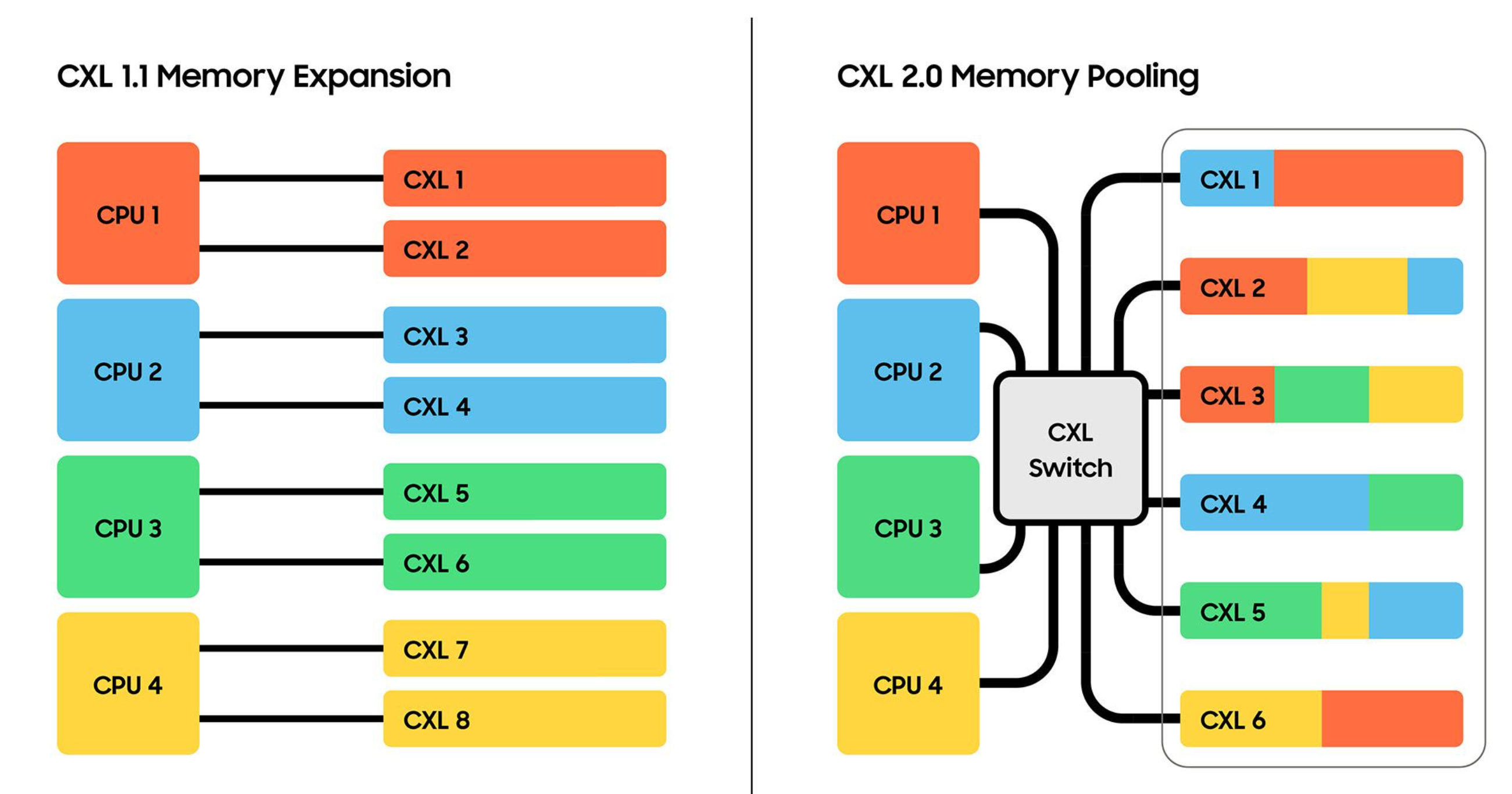
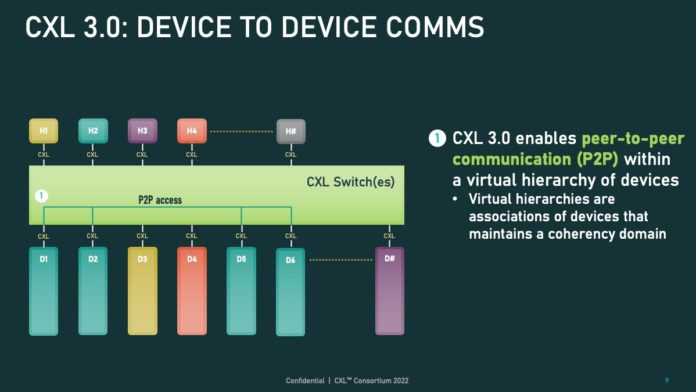
CXL: - 1.0 仅 host-centric。 - 2.0 支持 CXL switching 和 Memory Pooling,需要在PCIE switch硬件的基础上进行改造变为CXL switch才能支持CXL switching功能。 - 3.0 支持 CXL p2p 和 Memory Sharing。
考虑NIC¶
案例NIC:Nvidia ConnectX-7。

QSFP112¶
CX7 在 Tray 上通过 PCIE 接入 PCIE Switch 接收来自其他 Endpoint 的数据,然后通过QSFP112接入 Ethernet 以太网 或者 InfiniBand 和其他CX7进行通讯。
QSFP112 插口 1. 4lane 2. 112Gb/s 每 lane 3. 每个lane 高速串行差分全双工 4. 单向总带宽 56GB/s
DAC(Direct Attach Copper)铜缆用于连接两个CX7。 连接距离:无源7m,主动DAC10m。
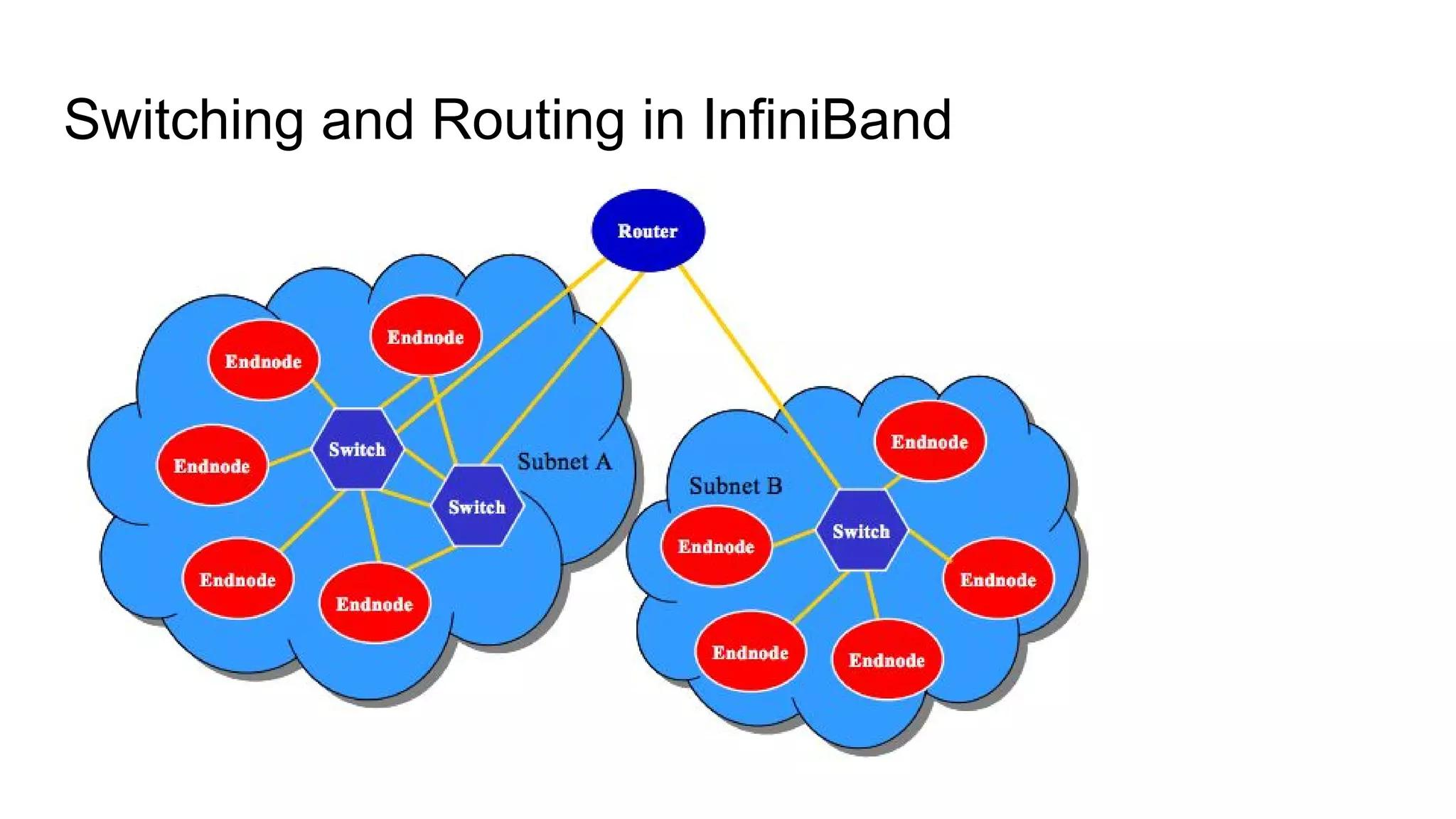
InfiniBand¶
-
节点:HCA、Switch、Router都是一种节点。
- HCA:Host Channel Adapter。
- HCA将PCIE树内部和外部连接起来。
- 多个节点之间构成的网络靠Fabric。
- Infinite 是一种 Fabric。
-
IB Switch 是 Infinite 网络中的交换机,内部有一颗单独设计的芯片,和PCIE Switch芯片不同。
- 节点之间通过IB Switch连接起来组成Fabric。
-
IB 子网是一片受统一管理的 IB 网络。
- 一个 Subnet Manager 实例管理 一个 IB 子网。每个Subnet只有一个Active SM。
- SM 发现拓扑、分配LID地址、配置转发表和管理端口状态。
- SM 会发送 管理报文去查询信息,包括节点、端口、Switch、Router,然后逐步建立整张Fabric的拓扑图。
- SM 实例运行在某台 IB Switch 上,这台IB Switch不光会管理自己,还会管理整片子网中的其他IB Switch和端口。
- 一个CX7内部可以有一个或多个端口(实体连接点/插线口),IB Switch上也可能有一个或多个端口。
- 每个端口/实体连接点/插线口实际上还预先设定了一个全球唯一的固定的GUID(类似MAC地址)。
- LID是子网内部分配给某个端口的地址,只在IB子网内部有效。
- 某个端口发送报文时会包含SLID(Source)和DLID(Destination)。
- 当交换机接受到报文后会查表,然后将DLID路由到正确的端口转发出去。
-
IB 子网之间依靠 IB Router连接,Router 也是一颗单独设计的芯片,和IB Switch不同。
-
UFM 是 Nvidia Unified Fabric Manager。
- 带内指的MAD走IB网络,带外指的是MAD走以太网。
- UFM在带内可以通过 MAD (IB managemant Datagram)管理整个Fabric。
- 带内可以实现监控Fabric拓扑、端口状态。
- UFM在带外通过以太网管理设备。
- 带外可以实现监控Switch设备的性能,为Switch设备升级。
专用服务器上跑一个Linux,Linux上跑UFM软件。
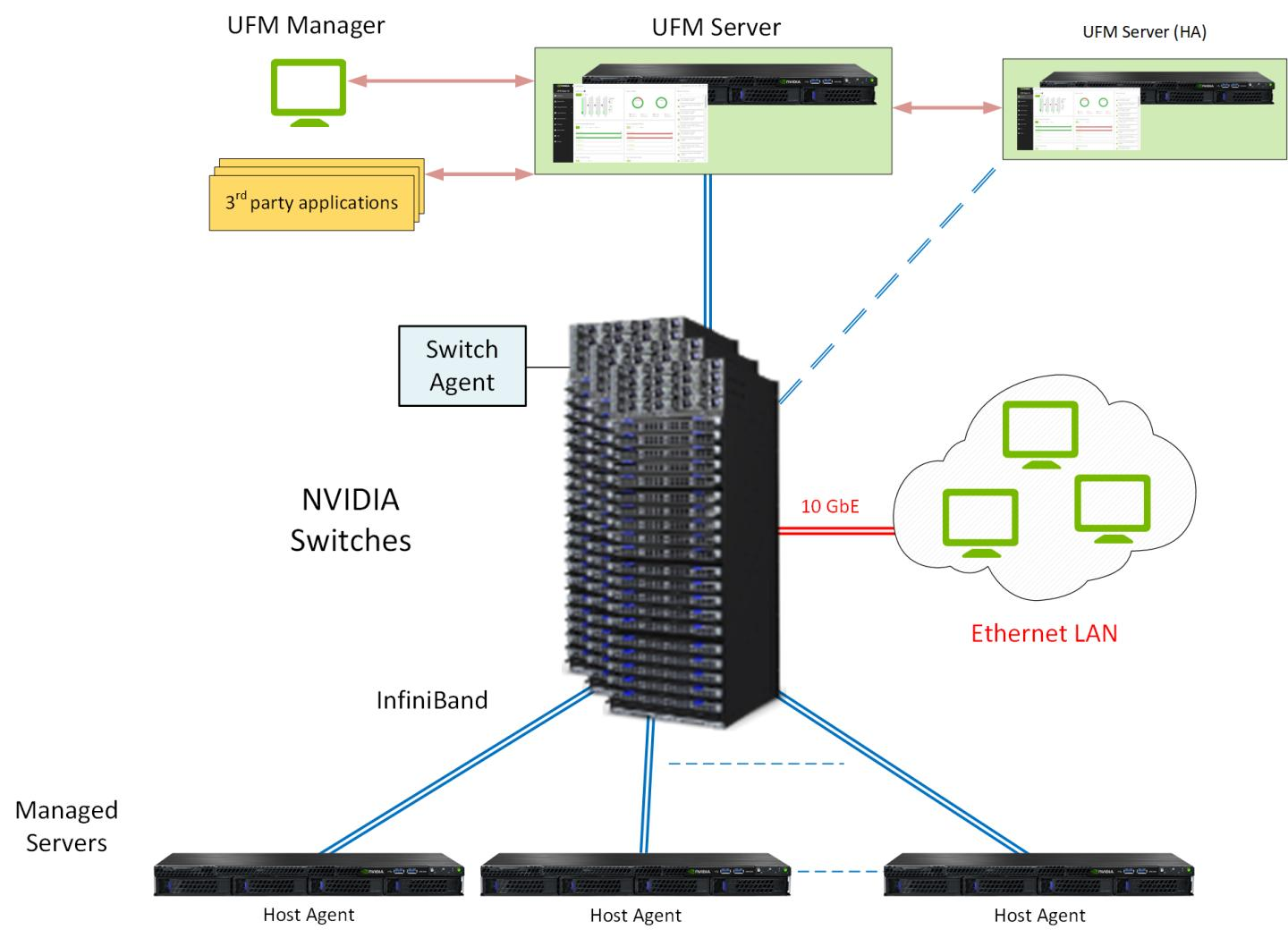
- HA表示High Availability(高可用),备份。
- GbE 表示 千兆以太网。
- MLNX-OS 是IB Switch 里的操作系统
- Switch Agent 是 MLNX-OS 中运行的Agent软件。
- Switch上同时接IB和Eth。
对于IB网络 -- in-band: - 数据交流 - HCA - IB Switch(SM和普通路由) - in-band 管理 Fabric - UFM(MAD)
对于Ethernet网络 -- out-of-band: - IB Switch(MLNX-OS + Switch Agent) - UFM
带宽¶
对CX7来说,输入是PCIe 5.0 x16 单向带宽 63GB/s,输出是QSPF 112 单向带宽 56GB/s 基本实现输入输出带宽持平。
对于IB Switch来说:使用 Nvidia Quantum-2 交换机。 - 使用OSFP插口(Octal Small Form-factor Pluggable),400Gb/s 50GB/s,处于NDR速率代际(HDR是200Gb/s一代)。 - 一共64个端口 - 如果64个端口内部形成了32个互不重叠的通信链路,则可以达到近似 32 个 400Gb/s 的单向吞吐。 - 带宽是链路理论上的最大传输能力,吞吐是实际运行中的收发能力。 - Switch的实际吞吐还和实际负载有关。比如某个输出端口需要同时处理多个输入端口的数据。
RDMA¶
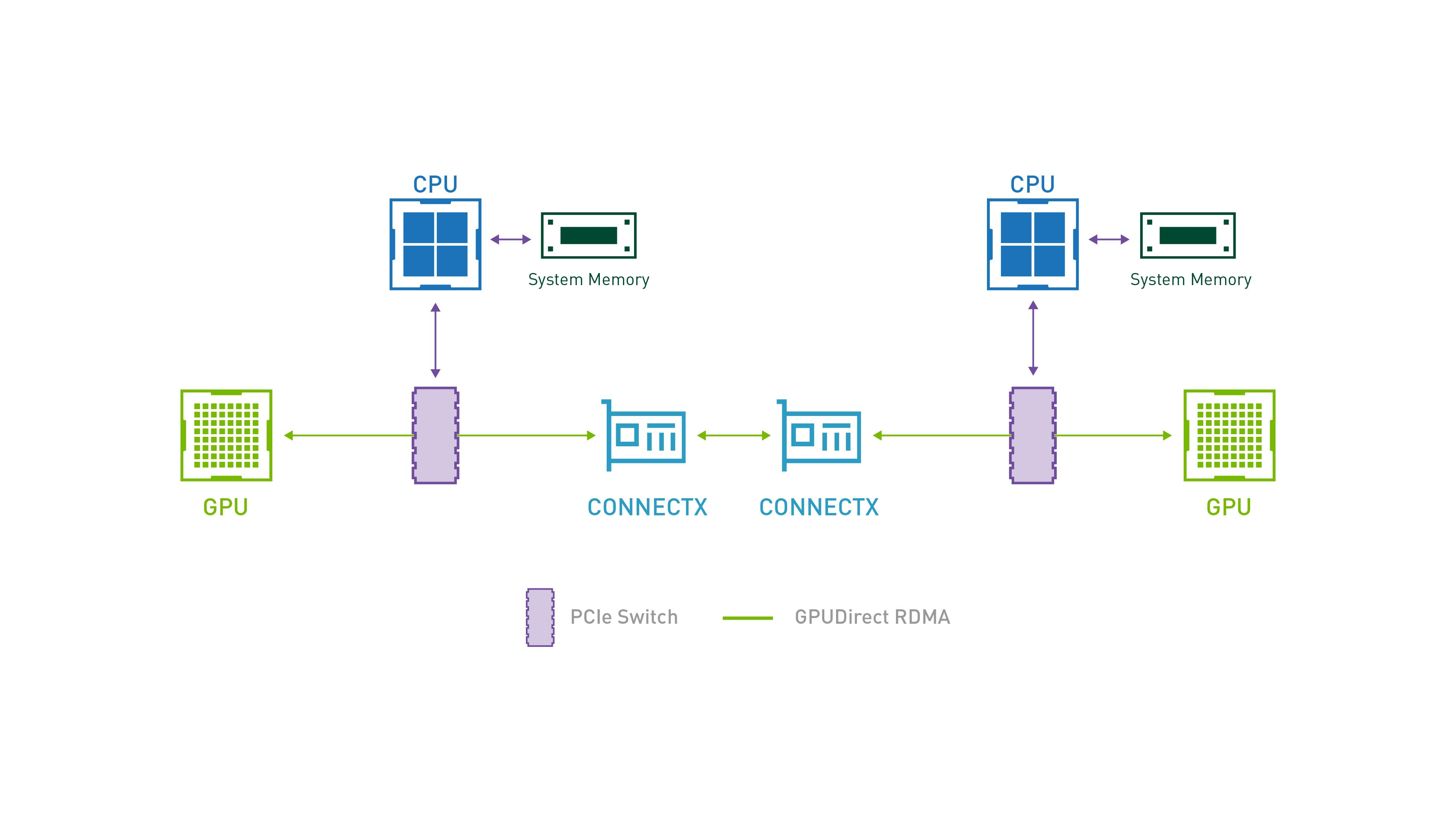
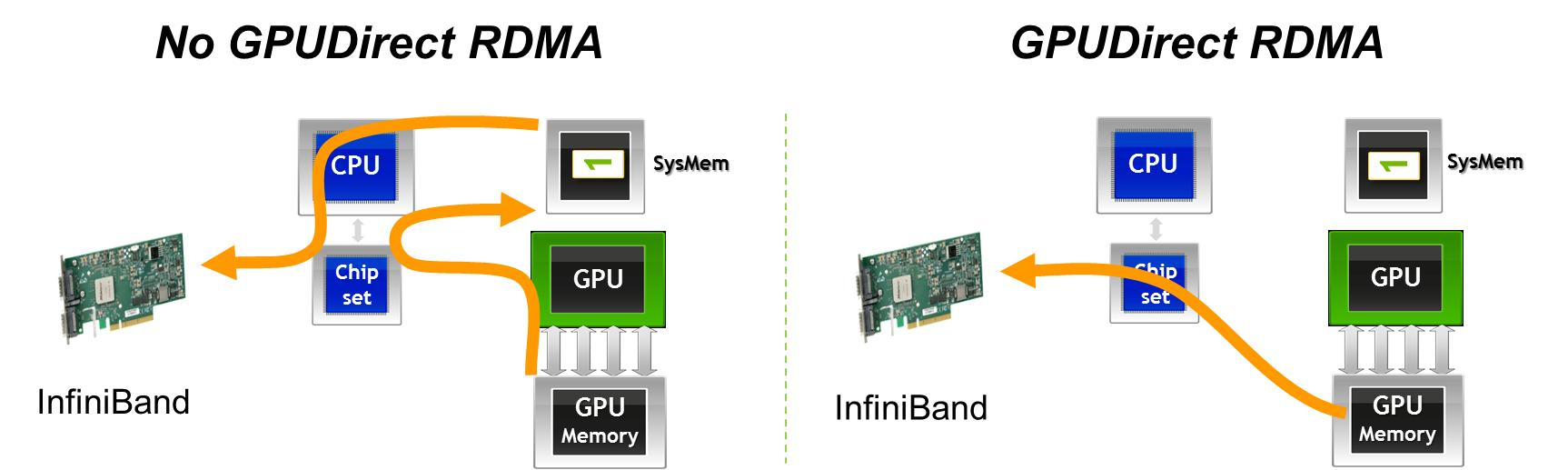
在本场景中:
- 一台主机可理解为“一个 RC 及其管理的本地 PCIe 树、设备和软件域”。
- A 主机包含 RC-A、GPU-A、HCA-A,B 主机包含 RC-B、GPU-B、HCA-B,两侧 HCA 通过 InfiniBand 互连。
- 相对某侧 HCA 而言,其所在主机是“本机”,另一侧是“远端”。
RDMA 是远程内存访问语义:一台机器可直接读写另一台机器已注册内存。
GPUDirect RDMA 则是 NVIDIA 提供的本地数据通路能力,使 HCA 能经 PCIe P2P/DMA 直接访问 GPU 显存。
RDMA 通信常见三类操作:SEND/RECV、RDMA WRITE、RDMA READ。
- 其核心对象包括:QP(通信端点,含 SQ/RQ)
- CQ(完成队列)
- MR(注册内存区域)
- PD(本机资源保护边界)
- lkey/rkey(本地/远端访问凭证)。
两端先交换 QP 连接信息建立链路;若 A 要访问 B 的 GPU Buffer,A 还必须拿到 B 暴露的 remote_addr + rkey。
以 RDMA WRITE(A GPU → B GPU) 为例:
1. A 侧 CPU软件向 QP-A 的 SQ 投递一个 WQE,其中包含 opcode、本地地址、lkey、remote_addr、rkey、长度 等字段;
2. CPU 通过 doorbell/MMIO 通知 HCA-A。
3. 随后,HCA-A 依据 WQE,经 PCIe DMA 从 GPU-A 显存取数,封装成 IB/RDMA 报文发往 HCA-B;
4. HCA-B 校验 rkey + remote_addr 后,经 PCIe DMA 将数据写入 GPU-B 显存;
5. 完成后写入 CQE。
因此数据路径是:GPU-A --PCIe DMA--> HCA-A --InfiniBand--> HCA-B --PCIe DMA--> GPU-B。
需要强调:QP、CQ、MR 不是只存在于 CPU 内存,也不是只存在于 HCA 芯片,它们是 RDMA 逻辑对象,状态分布在主机软件栈、HCA 上下文以及 DMA 可访问内存中。 - CPU 负责控制:创建对象、注册内存、填写 WQE、通知 HCA; - HCA 负责数据面:读取 WQE、执行 DMA、完成协议处理并写 CQE。 - 所谓“PCIe 到 IB 的转换”本质上由 HCA 完成,而不是主机软件搬运数据。 - CPU 负责下发命令,WQE 是命令本体,HCA 负责执行,CQE 是执行结果。